So you know about artificial intelligence, but what do you know about natural intelligence? It’s not a trick question—it’s the very reason we founded this company. We’ve turned decades of AI innovation on its head by asking how we can make AI work more like humans think.
Brains make sense of the world with patterns. Inspired by the human neo-cortex, our machine learning model, the Natural Intelligence Machine Learning system (NIML), is pattern-based.
NIML generates patterns from data, speeding up both the learning and interpretation of models. Data scientists get explainable, state-of-the-art results using a fraction of the data required by mainstream machine learning models. NIML also continuously learns from new observations in inference, reduces the need for data cleaning, and produces results that are “explainable,” unlike most machine learning systems on the market now (see our recent blog post on explainability to find out more.)
Natural Intelligence simply works more naturally, with better results, using less data and delivering more explainability to data scientists who need to know both the answer and the reason the answer makes sense. Here’s how it works.
How the NIML Pipeline Works
Buckle up—we’re going to take you on a ride through our pattern-based system. Spoiler: it’s a smooth ride, and data scientists love the scenery.
The NIML pipeline has three main components: the Encoder, the Neural Processor, and the Classifier.
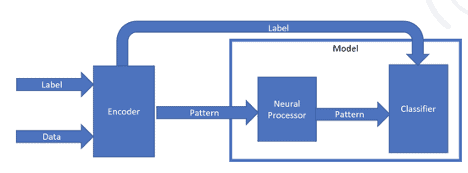
Incoming data has its optional label split off before being sent first to the encoder, then to the neural processor, and finally the classifier
Step 1: Encoder
The first part of our pipeline is the encoder. The encoder converts raw input into an initial set of patterns in Sparse Distributed Representation (SDR) format from the raw input values. Input data can be numeric or categorical, and it can be either raw data or engineered features. When the encoding is complete, the data are now pattern-based.
Step 2: Neural Processor
Once encoded patterns are created, the data travels to the second part of our pipeline, the Neural Processor, the mechanism within our model where the learning takes place. During training, the Neural Processor ‘learns’ frequently occurring combinations within the encoded patterns and consolidates these into a response pattern. This is similar to the brain’s neocortex, where specific areas of the brain light up when encountering environmental inputs.
When Pavlov’s trained dog was presented with food and the sound of a bell, specific synapses in the dog’s brain fired in a specific combination. The neural processor’s design allows a similar process to take place, where a specific pattern gets created when encoded inputs are observed together.
Like the brain, the Neural Processor’s learning algorithm doesn’t involve complex mathematics. We’re talking about simple algebra, not complex differential equations or functions. This is the essence of pattern-based AI. Simply put, patterns appear together over time, which reinforces these patterns. Identifying intricate patterns in data becomes much more efficient and the learning mechanism becomes much easier to understand when the data are shifted to a pattern-based coordinate system.
Step 3: Classifier
After these frequently occurring patterns are learned, they progress to the final stage of the pipeline for clustering and classifying. Like magnets, similar patterns gather together, and a unique signature emerges from elements that most frequently ‘light up’ together. The classifier provides an optional labeling piece, where a ground truth label is assigned to each of the signatures.
NIML and Inference
The steps so far have explained what takes place during model training. During inference, a new observation follows the same process of creating a pattern using the Neural Processor then comparing it to signature patterns that were created during training. The signature with the best match is returned. If the signature meets a specified minimum criterion, its corresponding class is predicted. If the minimum criteria is not met, an “unknown” class is reported as an anomaly or potential new class.
Familiar Interface
The look and feel of the NIML system will be familiar to the data scientist and machine learning practitioner. NIML runs in Python and follows the syntax of many of today’s popular packages like SciKit Learn or Keras. We are currently offering our model in the cloud through AWS.
Unique Benefits of Pattern-Based AI
We’ve found that by shifting to a pattern-based approach, we create unique benefits for data scientists:
Higher Tolerance of Common Data Issues aka Less Data Wrangling!
The NIS system can form meaningful patterns without massive amounts of training data. It also requires less data preparation, or time spent imputing missing data, or transforming data to be on the same scale. The pattern-based approach is also considerably more tolerant of noise without any modifications being made. As a result, the amount of time a data scientist spends performing data wrangling is significantly reduced.
Unbalanced Data? No Problem!
I mentioned before that the NIML system has no weights that require optimization. As a result, the learning that takes place here is highly resistant to having imbalanced classes in the data. Patterns get created whether there are 1 or 1,000,000 instances representing it, and as similar data come in, the connections get reinforced iteratively.
Anomaly Detection
Should the system encounter an anomalous object, it will isolate this object to provide the user an opportunity to investigate the object in greater detail. The pattern-based approach allows multiple classes of unknown objects to emerge without any additional training or effort, saving you time and money.
Less Maintenance
The continuous learning feature of our system, when turned on, allows learning to continue when deployed in the field. As data begins to drift, the system adapts and reinforces connections to the new areas in the input space without any need of taking it down for retraining.
Explainable AI
The learning component of our system has unique properties that allow decisions to be traced back to raw inputs. As a result, researchers can interpret the model’s decisions by seeing how they trace back to the raw inputs. Researchers can also better understand anomalies when they occur. Unlike other methods, there is no trade-off between accuracy and interpretability. (Check out more about our model’s explainability here.)
We think our pattern based model is going to transform what people think AI can do—and we’re already testing that with beta customers. You should check it out—drop us a line to get a demo!
